Symposium - 2013 - Privacy and Big Data
Privacy Substitutes
Jonathan Mayer & Arvind Narayanan *
Introduction
Debates over information privacy are often framed as an inescapable conflict between competing interests: a lucrative or beneficial technology, as against privacy risks to consumers. Policy remedies traditionally take the rigid form of either a complete ban, no regulation, or an intermediate zone of modest notice and choice mechanisms.
We believe these approaches are unnecessarily constrained. There is often a spectrum of technology alternatives that trade off functionality and profit for consumer privacy. We term these alternatives “privacy substitutes,” and in this Essay we argue that public policy on information privacy issues can and should be a careful exercise in both selecting among, and providing incentives for, privacy substitutes.[1]
I. Disconnected Policy and Computer Science Perspectives
Policy stakeholders frequently approach information privacy through a simpleinte balancing. Consumer privacy interests rest on one side of the scales, and commercial and social benefits sit atop the other.[2]Where privacy substantially tips the balance, a practice warrants prohibition; where privacy is significantly outweighed, no restrictions are appropriate. When the scales near equipoise, practices merit some (questionably effective[3]) measure of mandatory disclosure or consumer control.[4]
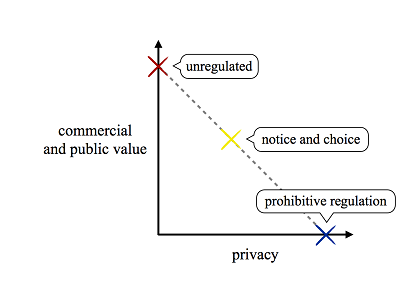
Computer science researchers, however, have long recognized that technology can enable tradeoffs between privacy and other interests. For most areas of technology application, there exists a spectrum of possible designs that vary in their privacy and functionality[5] characteristics. Cast in economic terms, technology enables a robust production-possibility frontier between privacy and profit, public benefit, and other values.
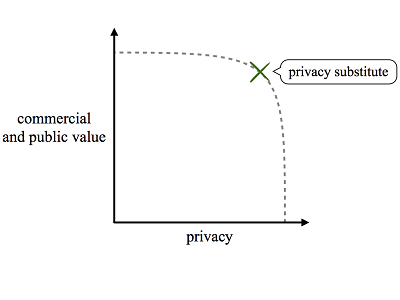
The precise contours of the production-possibility frontier vary by technology application area. In many areas, privacy substitutes afford a potential Pareto improvement relative to naïve or status quo designs. In some application areas, privacy substitutes even offer a strict Pareto improvement: privacy-preserving designs can provide the exact same functionality as intrusive alternatives. The following Subparts review example designs for web advertising, online identity, and transportation payment to illustrate how clever engineering can counterintuitively enable privacy tradeoffs.
A. Web Advertising
In the course of serving an advertisement, dozens of third-party websites may set or receive unique identifier cookies.[6] The technical design is roughly akin to labeling a user’s web browser with a virtual barcode, then scanning the code with every page view. All advertising operations—from selecting which ad to display through billing—can then occur on advertising company backend services. Policymakers and privacy advocates have criticized this status quo approach as invasive since it incorporates collection of a user’s browsing history.[7] Privacy researchers have responded with a wide range of technical designs for advertising functionality.[8]
Frequent buyer programs provide a helpful analogy. Suppose a coffee shop offers a buy-ten-get-one-free promotion. One common approach would be for the shop to provide a swipe card that keeps track of a consumer’s purchases, and dispenses rewards as earned. An alternative approach would be to issue a punch card that records the consumer’s progress towards free coffee. The shop still operates its incentive program, but note that it no longer holds a record of precisely what was bought when; the punch card keeps track of the consumer’s behavior, and it only tells the shop what it needs to know. This latter implementation roughly parallels privacy substitutes in web advertising: common elements include storing a user’s online habits within the web browser itself, as well as selectively parceling out information derived from those habits.

Each design represents a point in the spectrum of possible tradeoffs between privacy—here, the information shared with advertising companies—and other commercial and public values. Moving from top to bottom, proposals become easier to deploy, faster in delivery, and more accurate in advertisement selection and reporting—in exchange for diminished privacy guarantees.
B. Online Identity
Centralized online identity management benefits consumers through both convenience and increased security.[9] Popular implementations of these “single sign-on” or “federated identity” systems include a sharp privacy drawback, however: the identity provider learns about the consumer’s activities. By way of rough analogy: Imagine going to a bar, where the bouncer phones the state DMV to check the authenticity of your driver’s license. The bouncer gets confirmation of your identity, but the DMV learns where you are. Drawing on computer security research, Mozilla has deployed a privacy-preserving alternative, dubbed Persona. Through the use of cryptographic attestation, Persona provides centralized identity management without Mozilla learning the consumer’s online activity. In the bar analogy, instead of calling the DMV, the bouncer carefully checks the driver’s license for official and difficult-to-forge markings. The bouncer can still be sure of your identity, but the DMV does not learn of your drinking habits.
C. Transportation Payment
Transportation fare cards and toll tags commonly embed unique identifiers, facilitating intrusive tracking of a consumer’s movements. Intuitively, the alternative privacy-preserving design would be to store the consumer’s balance on the device, but this approach is vulnerable to cards being hacked for free transportation.[10] An area of cryptography called “secure multiparty computation” provides a solution, allowing two parties to transact while only learning as much about each other as is strictly mathematically necessary to complete the transaction.[11] A secure multiparty computation approach would enable the transportation provider to add reliably and deduct credits from a card or tag—without knowing the precise device or value stored.
II. Nonadoption of Privacy Substitutes
Technology organizations have rarely deployed privacy substitutes, despite their promise. A variety of factors have effectively undercut commercial implementation.
Engineering Conventions. Information technology design traditionally emphasizes principles including simplicity, readability, modifiability, maintainability, robustness, and data hygiene. More recently, overcollection has become a common practice—designers gather information wherever feasible, since it might be handy later. Privacy substitutes often turn these norms on their head. Consider, for example, “differential privacy” techniques for protecting information within a dataset.[12] The notion is to intentionally introduce (tolerable) errors into data, a practice that cuts deeply against design intuition.[13]
Information Asymmetries. Technology organizations may not understand the privacy properties of the systems they deploy. For example, participants in online advertising frequently claim that their practices are anonymous—despite substantial computer science research to the contrary.[14] Firms may also lack the expertise to be aware of privacy substitutes; as the previous Part showed, privacy substitutes often challenge intuitions and assumptions about technical design.
Implementation and Switching Costs. The investments of labor, time, and capital associated with researching and deploying a privacy substitute may be significant. Startups may be particularly resource constrained, while mature firms face path-dependent switching costs owing to past engineering decisions.
Diminished Private Utility. Intrusive systems often outperform privacy substitutes (e.g., in speed, accuracy, and other aspects of functionality), in some cases resulting in higher private utility. Moreover, the potential for presently unknown future uses of data counsels in favor of overcollection wherever possible.
Inability to Internalize. In theory, consumers or business partners might compensate a firm for adopting privacy substitutes. In practice, however, internalizing the value of pro-privacy practices has proven challenging. Consumers are frequently unaware of the systems that they interact with, let alone the privacy properties of those systems; informing users sufficiently to exercise market pressure may be impracticable.[15] Moreover, even if a sizeable share of consumers were aware, it may be prohibitively burdensome to differentiate those consumers who are willing and able to pay for privacy. And even if those users could be identified, it may not be feasible to transfer small amounts of capital from those consumers. As for business partners, they too may have information asymmetries and reflect (indirectly) lack of consumer pressure. Coordination failures compound the difficulty of monetizing privacy: without clear guidance on privacy best practices, users, businesses, and policymakers have no standard of conduct to which to request adherence.
Organizational Divides. To the extent technology firms do perceive pressure to adopt privacy substitutes, it is often from government relations, policymakers, and lawyers. In some industries the motivation will be another step removed, filtering through trade associations and lobbying groups. These nontechnical representatives often lack the expertise to propose privacy alternatives themselves or adequately solicit engineering input.[16]
Competition Barriers. Some technology sectors reflect monopolistic or oligopolistic structures. Even if users and businesses demanded improved privacy, there may be little competitive pressure to respond.
III. Policy Prescriptions
Our lead recommendation for policymakers is straightforward: understand and encourage the use of privacy substitutes through ordinary regulatory practices. When approaching a consumer privacy problem, policymakers should begin by exploring not only the relevant privacy risks and competing values, but also the space of possible privacy substitutes and their associated tradeoffs. If policymakers are sufficiently certain that socially beneficial privacy substitutes exist,[17] they should turn to conventional regulatory tools to incentivize deployment of those technologies.[18] For example, a regulatory agency might provide an enforcement safe harbor to companies that deploy sufficiently rigorous privacy substitutes.
Policymakers should also target the market failures that lead to nonadoption of privacy substitutes. Engaging directly with industry engineers, for example, may overcome organizational divides and information asymmetries. Efforts at standardization of privacy substitutes may be particularly effective; information technology is often conducive to design sharing and reuse. We are skeptical of the efficacy of consumer education efforts,[19] but informing business partners could alter incentives.
Finally, policymakers should press the envelope of privacy substitutes. Grants and competitions, for example, could drive research innovations in both academia and industry.
Conclusion
This brief Essay is intended to begin reshaping policy debates on information privacy from stark and unavoidable conflicts to creative and nuanced tradeoffs. Much more remains to be said: Can privacy substitutes also reconcile individual privacy with government intrusions (e.g., for law enforcement or intelligence)?[20] How can policymakers recognize privacy substitute pseudoscience?[21] We leave these and many more questions for another day, and part ways on this note: pundits often cavalierly posit that information technology has sounded the death knell for individual privacy. We could not disagree more. Information technology is poised to protect individual privacy—if policymakers get the incentives right.
- The area of computer science that we discuss is sometimes referenced as “privacy enhancing technologies” or “privacy-preserving technologies.” We use the term “privacy substitutes” for clarity and precision.
- See, e.g., Balancing Privacy and Innovation: Does the President’s Proposal Tip the Scale?: Hearing Before the Subcomm. on Commerce, Mfg., & Trade of the H. Comm. on Energy & Commerce , 112th Cong. 4 (2012) (statement of the Hon. Mary Bono Mack, Chairman, Subcomm. on Commerce, Mfg., & Trade) (“When it comes to the Internet, how do we—as Congress, as the administration, and as Americans—balance the need to remain innovative with the need to protect privacy?”), available at http://www.gpo.gov/fdsys/pkg/CHRG-112hhrg81441/pdf/CHRG-112hhrg81441.pdf; Fed. Trade Comm’n, Protecting Consumer Privacy in an Era of Rapid Change 36 (2012) (“Establishing consumer choice as a baseline requirement for companies that collect and use consumer data, while also identifying certain practices where choice is unnecessary, is an appropriately balanced model.”), available athttp://ftc.gov/os/2012/03/120326privacyreport.pdf.
- Recent scholarship has challenged the efficacy of current notice and choice models for technology privacy. See, e.g., Pedro Giovanni Leon et al., What Do Online Behavioral Advertising Privacy Disclosures Communicate to Users?,Proc. 2012 Assoc. for Computing Mach. Workshop on Privacy in the Electronic Soc’y 19, 19 (2012); see also Yang Wang et al., Privacy Nudges for Social Media: An Exploratory Facebook Study, Proc. 22d Int’l Conf. on World Wide Web763, 763 (2012).
- We depict notice and choice as a straight line since, in many implementations, consumers are given solely binary decisions about whether to accept or reject a set of services or product features. The diagrams in this Essay attempt to illustrate our thinking; they are not intended to precisely reflect any particular privacy issue.
- This includes speed, accuracy, usability, cost, technical difficulty, security, and more.
- See Jonathan R. Mayer & John C. Mitchell, Third-Party Web Tracking: Policy and Technology, Proc. 2012 IEEE Symp. on Security & Privacy 413, 415 (2012), available athttps://cyberlaw.stanford.edu/files/publication/files/trackingsurvey12.pdf.
- E.g., id. at 416-17.
- E.g., Michael Backes et al., ObliviAd: Provably Secure and Practical Online Behavioral Advertising, Proc. 2012IEEE Symp. on Security & Privacy 257, 258 (2012); Matthew Fredrikson & Benjamin Livshits, RePriv: Re-Imagining Content Personalization and In-Browser Privacy, Proc. 2011 IEEE Symp. on Security & Privacy 131, 131 (2011); Saikat Guha et al., Privad: Practical Privacy in Online Advertising, Proc. 8th USENIX Symp. on Networked Sys. Design & Implementation 169, 170 (2011); Vincent Toubiana et al., Adnostic: Privacy Preserving Targeted Advertising, Proc. 17th Network & Distributed Sys. Symp. 1, 2 (2010); Mikhail Bilenko et al., Targeted, Not Tracked: Client-Side Solutions for Privacy-Friendly Behavioral Advertising 13-14 (Sept. 25, 2011) (unpublished manuscript), available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1995127; Jonathan Mayer & Arvind Narayanan, Tracking Not Required: Advertising Measurement, Web Policy (July 24, 2012), http://webpolicy.org/2012/07/24/tracking-not-required-advertising-measurement; Arvind Narayanan et al., Tracking Not Required: Behavioral Targeting, 33Bits of Entropy (June 11, 2012, 2:42 PM), http://33bits.org/2012/06/11/tracking-not-required-behavioral-targeting; Jonathan Mayer & Arvind Narayanan, Tracking Not Required: Frequency Capping, Web Policy (Apr. 23, 2012),http://webpolicy.org/2012/04/23/tracking-not-required-frequency-capping.
- See Why Persona?, Mozilla Developer Network (May 10, 2013, 3:02 PM), https://developer.mozilla.org/en-US/docs/Mozilla/Persona/Why_Persona.
- See, e.g., Loek Essers, Android NFC Hack Enables Travelers to Ride Subways for Free, Researchers Say,Computerworld (Sept. 20, 2012, 12:29 PM),https://www.computerworld.com/s/article/9231500/Android_NFC_hack_enables_travelers_to_ride_subways_for_free_researchers_say.
- Secure multiparty computation has been implemented in various well-known protocols. The area traces its roots to Andrew Yao’s “garbled circuit construction,” a piece of “crypto magic” dating to the early 1980s. Researchers have used secure multiparty computation to demonstrate privacy-preserving designs in myriad domains—voting, electronic health systems and personal genetics, and location-based services, to name just a few. The payment model we suggest is based on David Chaum’s “e-cash.” His company DigiCash offered essentially such a system (not just for transportation, but for all sorts of payments) in the 1990s, but it went out of business by 1998. See generally How DigiCash Blew Everything, Next Mag., Jan. 1999, available at http://cryptome.org/jya/digicrash.htm.
- See generally Cynthia Dwork, Differential Privacy: A Survey of Results, Proc. 5th Int’l Conf. on Theory & Applications Models Computation 1, 2 (2008).
- Most production systems have data errors, in fact, but they are subtle and underappreciated. Differential privacy is ordinarily a matter of kind and degree of error, not whether error exists at all.
- See, e.g., Mayer & Mitchell, supra note 6 at 415-16. Some of these misstatements may, of course, reflect intentional downplaying of privacy risks for strategic advantage in public and policy debates.
- In theory, uniform privacy-signaling mechanisms or trust intermediaries might assist in informing users. In practice, both approaches have had limited value. See, e.g., Benjamin Edelman, Adverse Selection in Online “Trust” Certifications and Search Results, 10 Electronic Com. Res. & Applications 17 (2011) (studying efficacy of website certification providers); Adrienne Porter Felt et al., Android Permissions: User Attention, Comprehension, and Behavior, Proc. 8th Symp. on Usable Privacy & Security 2 (2012) (exploring usability of the Android device permissions model).
- We have observed firsthand the difficulty imposed by organizational divides in the World Wide Web Consortium’s process to standardize Do Not Track. Participants from the online advertising industry have largely been unable to engage on privacy substitutes owing to limited technical expertise, distortions in information relayed to technical staff, and inability to facilitate a direct dialog between inside and outside technical experts.
- Sometimes a rigorously vetted privacy substitute will be ready for deployment. Frequently, to be sure, the space of privacy substitutes will include gaps and ambiguities. But policymakers are no strangers to decisions under uncertainty and relying on the best available science.
- We caution against requiring particular technical designs. In the future, better designs may become available, or deficiencies in present designs may be uncovered. Cast in more traditional terms of regulatory discourse, this is very much an area for targeting ends, not means.
- See supra note 3.
- The congressional response to Transportation Security Administration full-body scanners might be considered an instance of a privacy substitute. Congress allowed the TSA to retain the scanners, but required a software update that eliminated intrusive imaging. 49 U.S.C. § 44901(l) (2011).
- For example, some technology companies are lobbying for European Union law to exempt pseudonymous data from privacy protections. See Ctr. for Democracy & Tech., CDT Position Paper on the Treatment of Pseudonymous Data Under the Proposed Data Protection Regulation (2013), available at https://www.cdt.org/files/pdfs/CDT-Pseudonymous-Data-DPR.pdf. Information privacy researchers have, however, long recognized that pseudonymous data can often be linked to an individual. See, e.g., Mayer & Mitchell, supra note 6, at 415-16.